Criando web scrapers de maneira rápida com Beautiful Soup

Opa, eae?
Recentemente tive que fazer um web scrapper simples (de preferência rápido) e me deparei com antigas tecnologias de raspagem de dados que já usei como Selenium e Scrapy e bom… Eles não são muito simples.
Se você já usou o Selenium sabe da dificuldade e da não praticidade de ter que instalar webdrivers, depois ter o seu bot rodando em um navegador não é nada muito elegante, muito menos performático.
Scrapy é de fato uma excelente ferramenta muito robusta para web scraping, porém ela não é muito prática, basta ver quantos arquivos ela gera para, nesse caso, um bot extremamente simples.
E foi ai que eu acabei me deparando com o Beautiful Soup.
Beautiful Soup

Beautiful Soup é uma biblioteca de Python para análise de documentos HTML e XML. O que ele faz é transformar o conteúdo do arquivo em uma árvore de ficheiros, assim fica mais fácil por meio dos métodos da própria lib pesquisar e modificar trechos do código HTML.
Para usarmos essa lib precisamos do nosso gerenciador de pacotes do Python o Pip e rodar o seguinte comando no terminal mais próximo:
pip install beautifulsoup4E é isso! Nada de projetos pré-prontos gigantes e com 300 arquivos. Bora codar!
Extraindo dados do Quotes to Scrape
Para quem não sabe o “Quotes to Scrape” é um site de citações de pessoas famosas feito justamente para treinar scraping. Ele não apresenta de fato grandes desafios que podem acontecer no trabalho de raspagem de sites mais complexos e que talvez que até tentem impedir automatizações, mas serve como um treino inicial para começar nesse mundo.
O objetivo aqui será vasculhar todas as páginas (10 no total) e procurar todas as citações a Albert Einstein.
Não irei fazer suspense, então segue o código:
from bs4 import BeautifulSoup
import requests
# URL of the page we want to scrape
url = "https://quotes.toscrape.com/page/"
initial_page = 1;
end_page = 10;
author = "Albert Einstein"
quotes = []
# Loop through the pages
for page in range(initial_page, end_page):
# Get the HTML content
response = requests.get(url + str(page))
# Create a BeautifulSoup object
soup = BeautifulSoup(response.text, "html.parser")
# Get the quotes
page_quotes = soup.find_all("div", class_="quote")
# Verify if the author is in the quote and save it
for quote in page_quotes:
if (quote.find("small", class_="author").text == author):
quote_text = quote.find("span", class_="text").text
quotes.append(quote_text)
print("Quote found: " + quote_text)
print("Number of quotes: " + str(len(quotes)))
Link para o código no GitHub: https://github.com/MarlonHenq/Web-Scraping-Quotes-to-Scrape-Beautiful-Soup
Extremamente simples, né? (ainda mais com um comentário a cada linha hahah)
Mas vamos de alguns pontos:
Bom, o BS não pega as informações da página diretamente da web, então a gente chama também a lib “requests” para poder pegar o conteúdo em texto do HTML da página por meio do requests.get().
Dado o código da página a gente faz a nossa sopa com BeautifulSoup(response.text, “html.parser”).
Aí é só aplicar os filtros! Selecionamos todos os quotes com soup.find_all(“div”, class_=”quote”). Marlon, como eu sei qual tag e classe devo pegar? Basta olhar o código dá página, inspecione o elemento de um quote com botão direito do mouse e tenha isso:
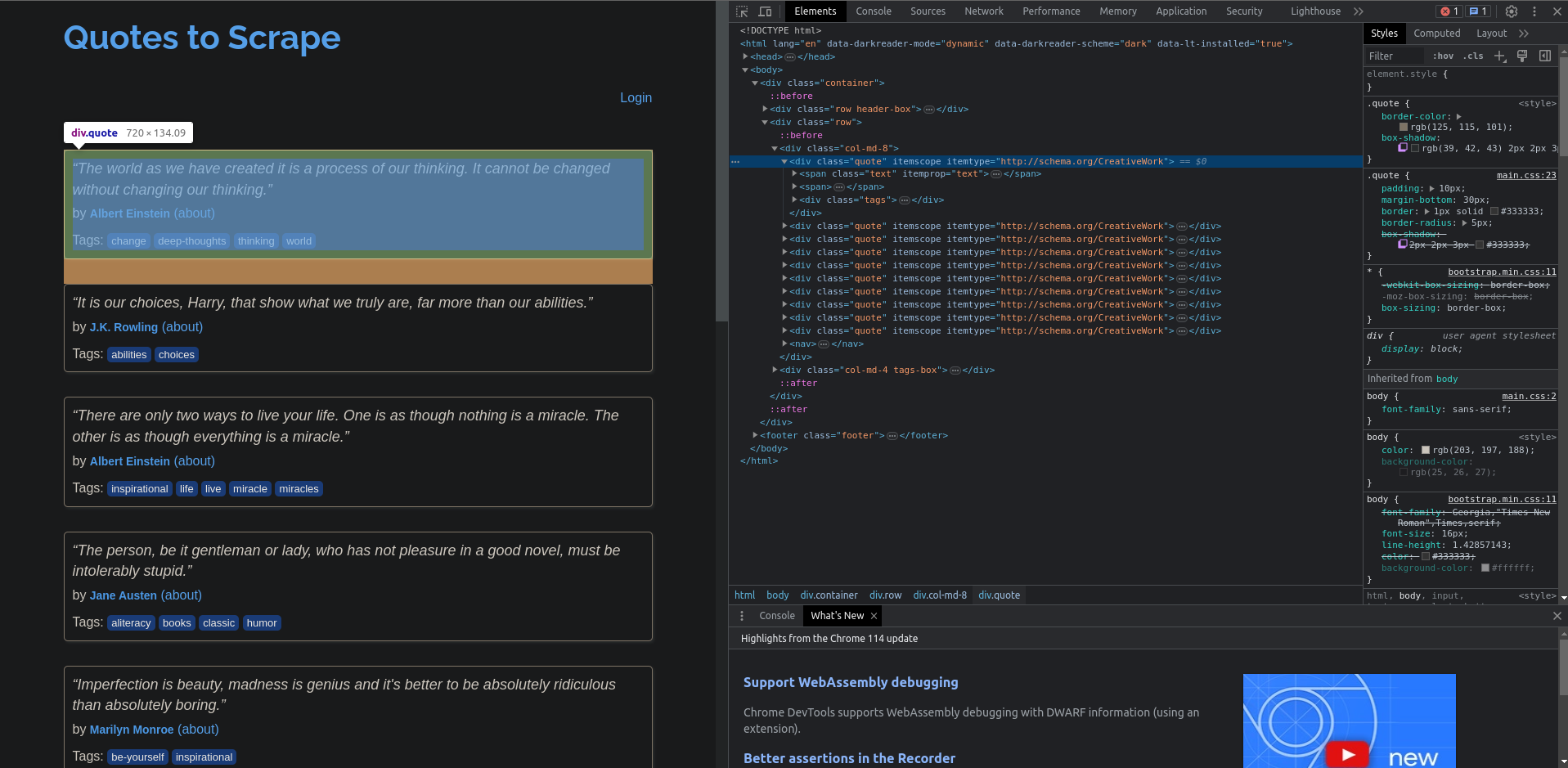
Possuindo todas as citações de uma página verificamos se o autor é o nosso querido cientista de língua para fora (Novamente basta olhar as tags e classes no código da página com o inspecionar elemento), e caso for salvamos na nossa lista de quotes e escrevemos a mensagem na tela.
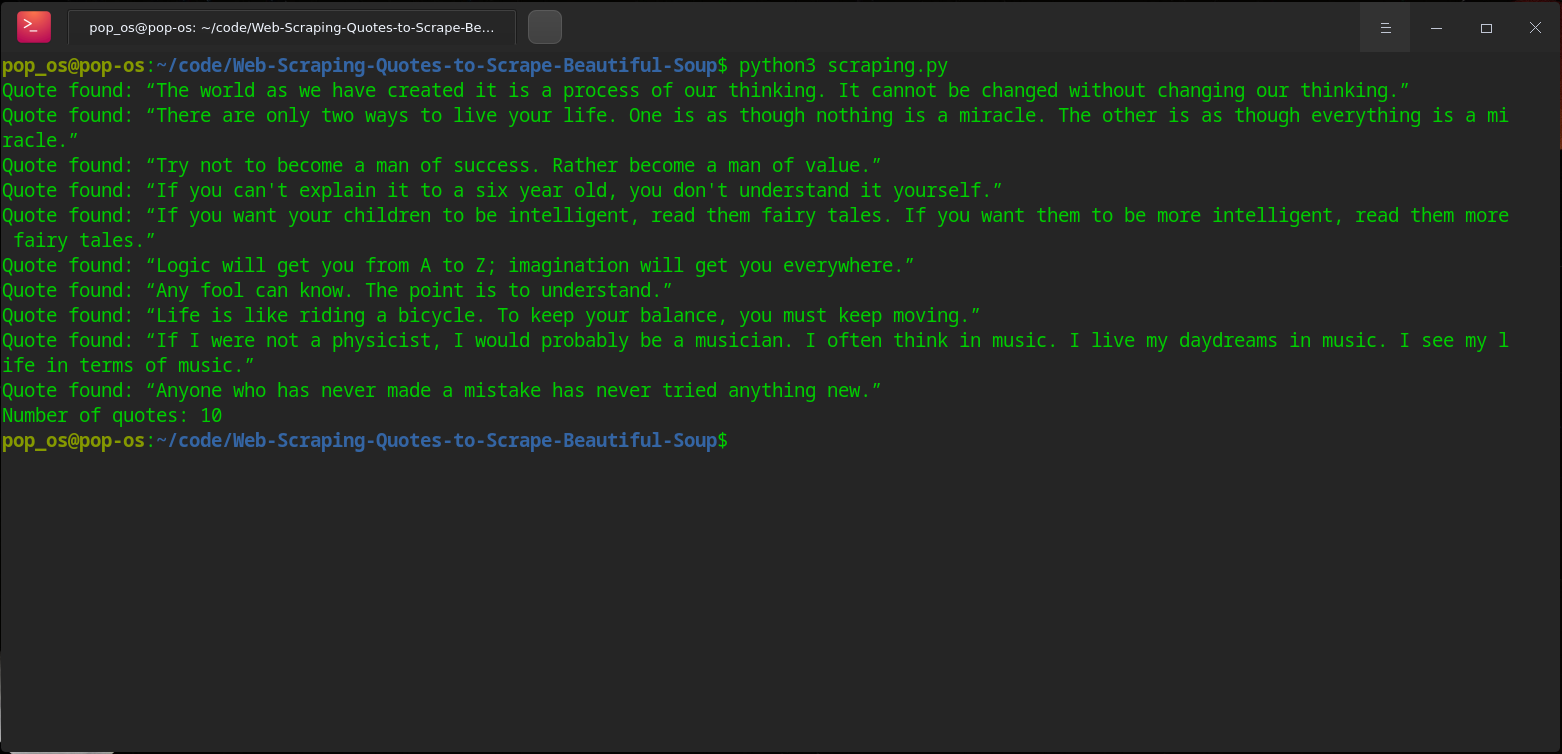
Bingo! Temos todas as frases de Einstein na tela!
Isso é tudo!
Post extremamente simples, de uma ferramenta muito útil no seu dia a dia.
Caso queira outro exemplo, tenho o código que me inspirou a fazer esse post, um raspador do ranking do HDLBits disponível em: https://github.com/MarlonHenq/Web-Scraping-HDLBits-profiles
Se gostou, não se esqueça de me seguir lá no Twitter para receber mais posts: @MarlonHenq
Aproveita e me responde lá se sopa é ou não janta.
Vou indo que minha sopa já está pronta!
